- 42 Books / 42 Years Blog Post 1: Stylometric Analysis
42 Books / 42 Years Blog Post 1: Stylometric Analysis
This post inaugurates a series of blog posts that use digital humanities methodologies to examine the books comprising History of Black Writing (HBW)’s 2025 exhibit 42 Books / 42 Years. 42 Books / 42 Years celebrates HBW’s 42nd anniversary by highlighting 42 important novels belonging to the history of African American and African diaspora literature, and embodies HBW’s commitment to the recovery and digital preservation of Black literary culture.
This blog is accompanied by the Stylometric Analysis Explorer, a web app that allows the reader to interact with the data used to generate the plots and graphs displayed below. Using the Stylometric Analysis Explorer, the user can:
-
manipulate the parameters of the analysis to generate different versions of the figures in this post;
-
zoom in on particular parts of the figures;
-
and obtain exact numerical information on the data underlying the plots and graphs.
In this way, the user can gain a deeper understanding of the reading below, and even come up with a reading of their own. Access the Stylometric Analysis Explorer, the companion piece to this blog, here.
Introduction: What is Stylometric Analysis, Anyway?
I would like to begin this series of blog posts on the 42 Books / 42 Years exhibition with a “distant”1 stylometric reading. Stylometry, in this context, is the statistical analysis of linguistic style in texts. The fundamental assumption of stylometry is that every author has unconscious habits of writing which embed themselves in such quantifiable patterns as the average length of the words they use (as measured in characters), the frequency with which they use certain words, the way they prefer to structure their sentences, and more. It follows from this assumption that information on an author’s styles can be retrieved by converting texts into quantitative data, such as word length distributions (which describe the frequency of words in different lengths in a text) and word frequency distributions (which describe, in a text, the frequency of the appearance of each word in a list of words).
Stylometry has a long history. T. C. Mendenhall’s 1887 article “The Characteristic Curves of Composition,” which can be called the first stylometric study, considers the word-length distribution of texts as a vector of their authors’ unconscious stylistic fingerprints.2 Mendenhall finds that the measure of word length preference can be used to distinguish between different authors, and suggests that this measure could be applied to determine the authors of works whose authorship is questioned.
Many contemporary stylometric studies follow in Mendenhall’s footsteps, working to attribute documents of disputed or unknown authorship to specific writers. As a case in point, in 2013, Duquesne University computer scientist Patrick Juola found evidence suggesting that J. K. Rowling wrote the detective novel The Cuckoo’s Calling under the pseudonym Robert Galbraith.3 Among other measures, Juola selected and calculated the occurrence of the 100 most frequent words (more on this metric of literary style below!) occurring in four texts by four authors; namely, Rowling’s The Casual Vacancy, Ruth Rendell’s The St. Zita Society, P.D. James’s The Private Patient, and Val McDermid’s The Wire in the Blood. Next, he calculated the occurrence of these words in The Cuckoo’s Calling. He found that The Cuckoo’s Calling resembled Rowling’s and McDermid’s novels the most. Considering this finding along with other measurements like a comparison of the word-length distributions of the five novels mentioned above, Juola concludes that The Cuckoo’s Calling is stylistically most akin to The Casual Vacancy.
Authorship attribution is not the only task stylometric analysis is useful for. Insofar as this kind of analysis produces information on the stylistic fingerprints of different authors, it can yield insight into the ways in which differences and similarities among authors manifest, and why that matters. Indeed, it is this employment of stylometric methods—and not authorship attribution—that figures as a cornerstone of computational literary studies scholarship.4 Authorship attribution as such does not give rise to the sort of reading that is key to literary studies. In comparison, interpreting the data produced by stylometric analysis as one interprets a book makes for a study of literature in the macro scale (hence serving as the “distant” counterpart of “close reading”). Thus, contrary to such studies as Mendenhall’s and Juola’s, this blog post aims to discover what we can learn from the stylistic (dis)similarities among the books in HBW’s 42 Books / 42 Years corpus.
Methodology
What I Did, How I Did It, and What It All Means
In this blog post, I will not bore you with the details of how I preprocessed the 42 novels, or the mathematical nuances of the stylometric methods I used. Rather, I will briefly touch on what stylometric method I used and why, as well as on what procedures of visualization I followed to make my data readable for a broad audience.
First, I placed each novel into a consistent naming schema. For example, I identified Nella Larsen’s Quicksand as W_Larsen_Quicksand_1928, and Paul Laurence Dunbar’s The Sport of the Gods as M_Dunbar_Sport_1902. M/W indicate the authors’ genders. This naming schema not only facilitates the visual separation of the novels based on their publication dates and their authors’ genders, but it also makes the novels’ authorial gender and publication date information visible on the screen all the time without cluttering any of the visualizations.
Next, I used the Python natural language processing (NLP) library spaCy to break each novel into individual tokens (or, in common parlance, words).5 I then converted each text into frequency distributions of the n most frequent words (MFW) in the corpus, starting from 100 MFW and ending at 2000, in increments of 100. I did this twice, once including stopwords, and once excluding them. “Stopwords,” a term used in NLP, refers to words with low semantic value and high frequency, such as pronouns and prepositions. They are generally not filtered out in stylometric analyses, since such words give insight into the unconscious stylistic fingerprints of authors. Still, filtering them out may produce intriguing results. (I will explore the impact of stopwords in more detail in the next blog post.) For both sets, I discarded proper nouns from the novels, as the use of common proper nouns may suggest a stylistic resonance between two novels where there is none. What I mean is: Novel A and Novel B may both have a character named Tom, but it is unlikely that these Toms are the same person.
Finally, I:
-
Calculated, for each novel, what percentage of the total text each word represents. Let’s say that a novel consists of 100,000 words in total: if 5,400 of these words are “the,” then “the” gets a percentage score of 5.4% for that novel.
-
Normalized these percentages in view of the entire corpus to give equal weight to high- and low-frequency words. To do this, I took the percentage of a word in a specific novel, subtracted the average percentage of that word across the whole corpus, and divided by its standard deviation. If 5.4% of a given novel is “the,” for example, I take the average percentage value of “the” across the corpus, subtract this corpus average percentage from 5.4%, and divide the result by the standard deviation of “the” across all the texts in the corpus. If the corpus average percentage is lower than 5.4%, then “the” gets a positive “z-score” value for that novel. (It would get a negative z-score if the percentages were reversed.)6
The data scaling technique described in the second step of the process above is called z-score normalization. Z-score normalization is necessary for this task because it equalizes the weight of every single word in a given MFW stratum. If I were to use raw percentages, then words with very high frequency would give no room for words with relatively lower frequency to influence the results in any of the MFW strata.
In sum, I converted the novels to normalized frequency distributions that measure how differently a novel is written from the rest of the novels in HBW’s corpus of 42 novels in terms of word frequency. It is important to note here that, when we look at lower frequency strata like 100 MFW (remember Juola?), we look almost exclusively at words with low semantic value. Words such as “the,” “to,” or “I”—which are called “function words”, as they perform grammatical work—are bound to dominate every English-language text, frequency wise. This will give us information on the unconscious style of texts. In comparison, when we look at higher MFW strata, we are looking at the content of texts along with their unconscious style. As we will see below, this has interesting implications with regard to gender as well as chronology.7
The Matter of Visualization
In order to acclimate the reader to the analysis conducted in this blog post, as well as to facilitate analysis for the reader, I want to provide a quick overview of the five visualization components of the Stylometric Analysis Explorer. I’ll note that I will rely primarily on the first of these components in this blog post.
These five components are:
- Principal Component Analysis (PCA) Plot: This component is a PCA plot, which, in short, puts our normalized frequency distributions on a two-dimensional plane. Think of it this way: a frequency distribution of 100 MFW is a 100-dimensional shape, which is impossible to visualize. PCA reduces those dimensions to two “principal components” (PCs). On this PCA plot, our 42 novels can be separated on the basis of gender and publication date.
- Distinctive Words (Top 5 -/+): This component displays the five most extreme negative and positive z-scores for each novel. This can show what words make a given novel different from the rest.
- Loadings (Top 10): This component displays the top 10 loadings for PC1 and PC2, the two principal components that make up the two dimensions of my PCA plot. A positive loading for a word means that the presence of this word contributes to the PC, whereas a negative loading means that the word’s absence contributes to the PC.
- Cluster Analysis: This component puts the novels into clusters on a dendrogram (tree graph) based on their stylometric distance from one another. To calculate the stylometric distance between any two novels, I measure the absolute difference between the two novels’ z-scores for each word, and add these individual gaps together.8 The novels are clustered in accordance with these pairwise distance measurements using a clustering algorithm called Ward linkage. It is difficult to explain what Ward linkage does without getting bogged down in mathematical details. The important element of Ward linkage for my analysis is that it minimizes variance; that is to say, in view of the pairwise distances, it aims to create the most tightly-knit stylistic clusters possible.
- Distance Heatmap: This component puts the pairwise distances between each novel on to a heatmap.
Analysis: Looking From Afar At Gender and Chronology
Now, let’s turn to a distant reading of the 42 books in our corpus using the stylometric methodology described above. In other words, let’s look at our data from afar. After all, that’s what computational methods allow us to do; it is difficult to perceive patterns in 42 books using a pair of human eyes, but not at all difficult using a computer. Since I talk about patterns, let’s look at the broad divisions of gender and chronology in that order, and see if they yield any patterns among our novels.
A Gender Divide: Light, Darkness, the City, Style
As Figure 1 shows, on lower MFW strata, there is not much difference between authors of different genders; everyone’s novel concentrates around the center of the plot. As the plot moves to the higher MFW strata, a slight division of genders starts to emerge in the center.
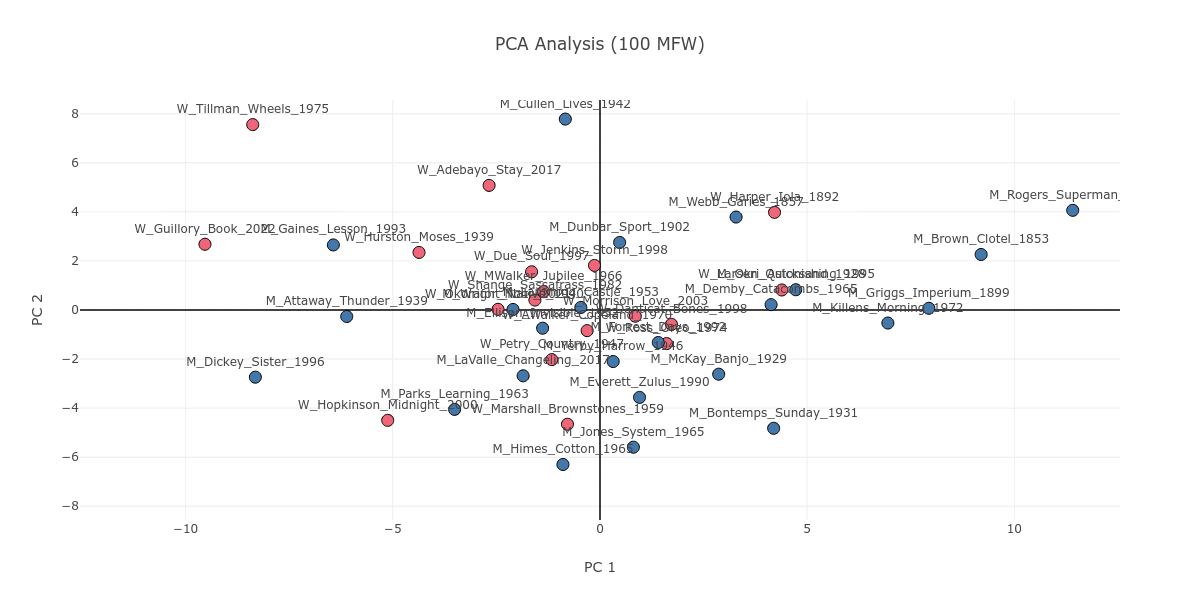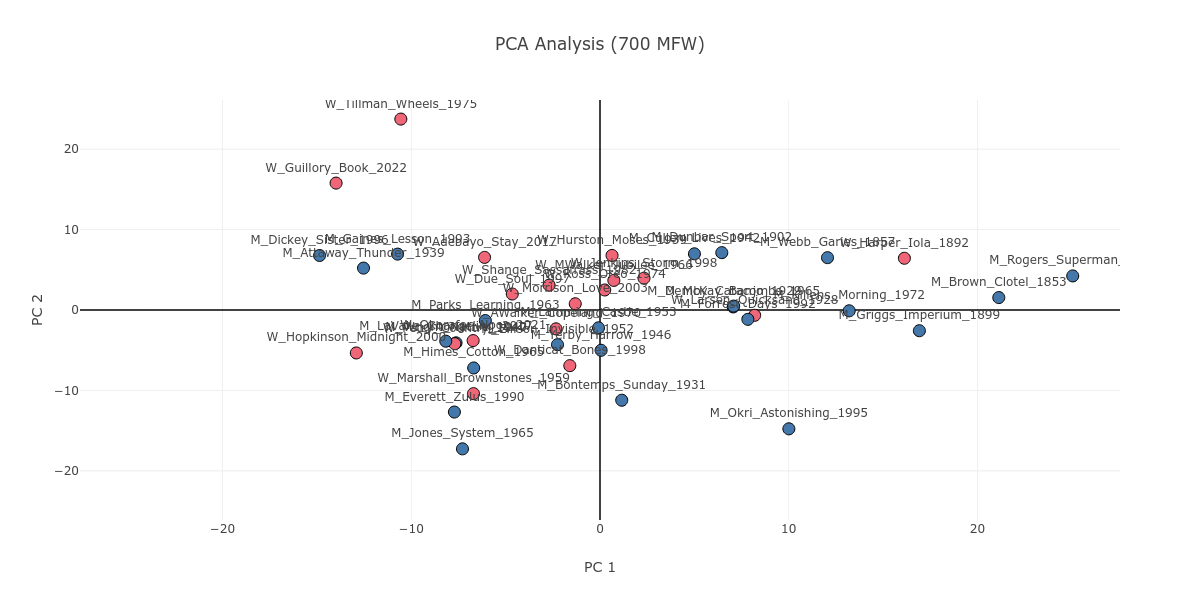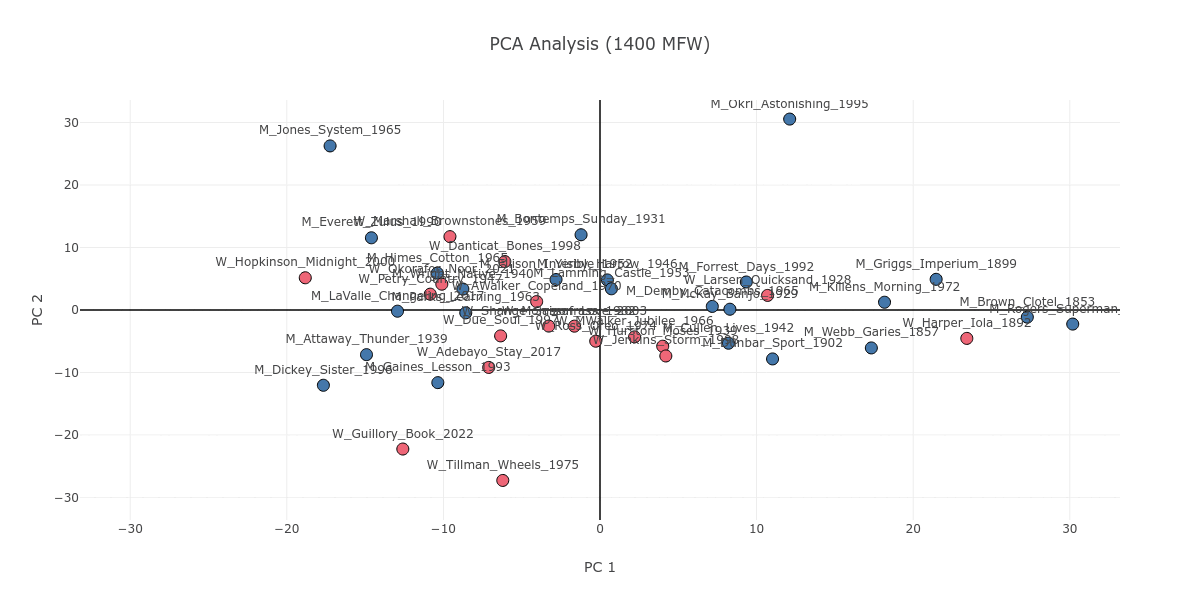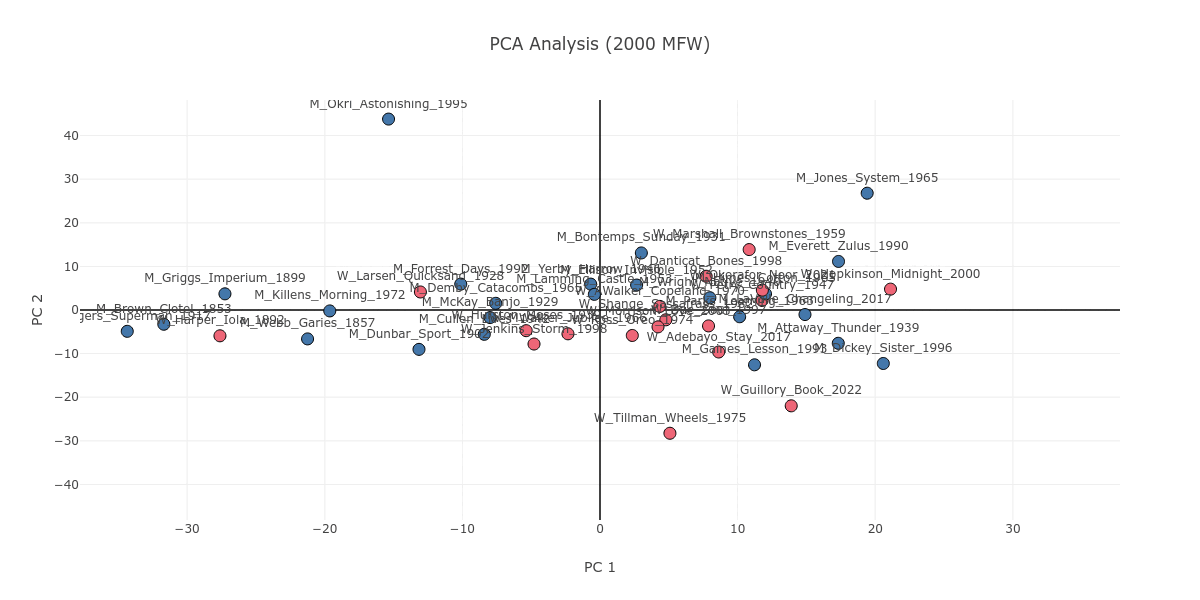
Figure 1. The PCA plot as it progresses from 100 to 2000 MFW, with the novels color coded as pink, if the author is a woman, or blue, if the author is a man.
On a surface level, this could suggest that men and women write about different things, as higher MFW strata include content-based information. However, it occurs to me that this gender division is not purely based on content in the sense of genre or theme. Let’s zoom in on the main manifestation of this division on the high MFW stratum of 1500. We can find corresponding books along the gender division in Figure 2, which zooms in near the center point of the PCA plot. On the basis of genre, the New Orleans romance of Frank Yerby’s The Foxes of Harrow (M_Yerby_Harrow_1946) can pair with the passionate historical romance of Beverly Jenkins’s Through the Storm (W_Jenkins_Storm_1998). Likewise, on the basis of theme, we can link together Fran Ross’s Oreo (W_Ross_Oreo_1974) and Ralph Ellison Invisible Man (M_Ellison_Invisible_1952), both of which concern identity struggles and the invisibility of the Black body.
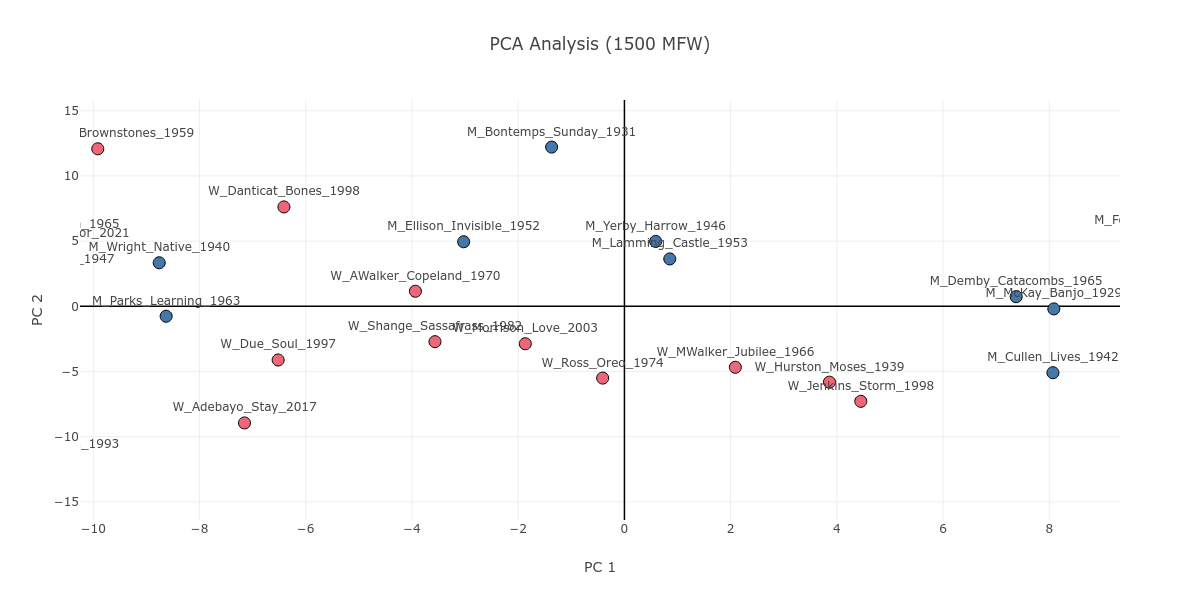
Figure 2. The PCA plot, zoomed in near the center of the 1500 MFW stratum.
Despite these generic and thematic affinities, these two pairs do not form two respective clusters on the plot; rather, they adhere to the gender division seen in Figure 2. Why? To answer this question, we can examine the top ten most significant loadings of the PC2 axis, where the division occurs. Figure 3 shows us a mix of high semantic value words serving as positive loadings, and low semantic value function words serving as negative loadings. The latter set of words suggest that there is, to an extent, an unconscious stylistic difference that manifests itself between novels by male and female authors.
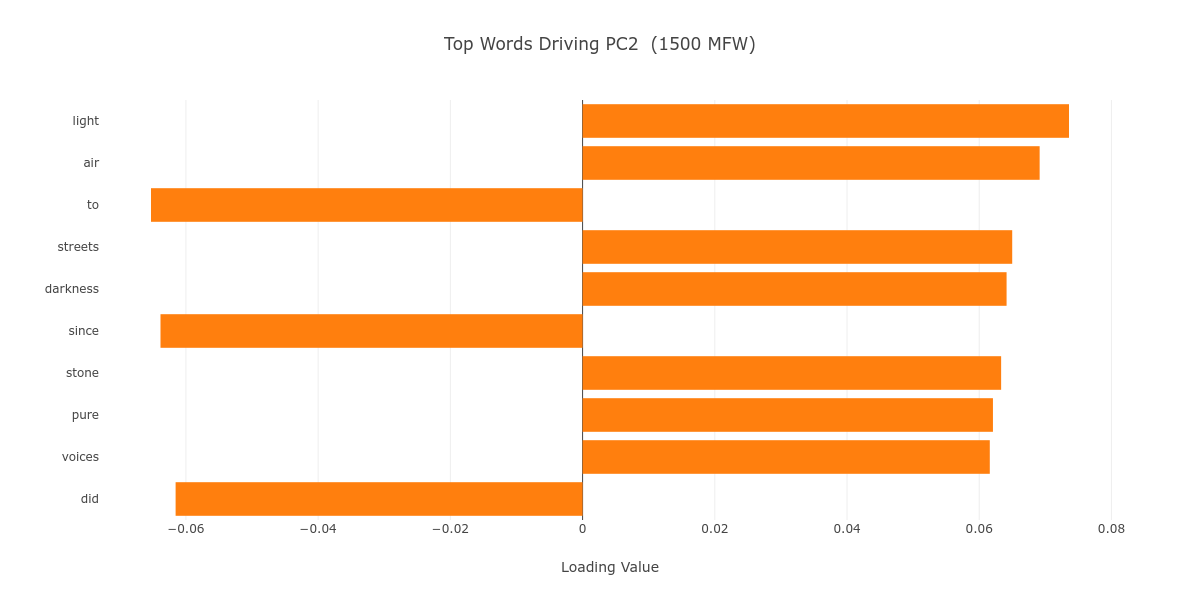
Figure 3. The top ten loadings of PC2 on the 1500 MFW stratum.
The former set of words is perhaps more interesting. For the sake of textual space, let’s limit our discussion to the first four high semantic value words on the list (light, air, streets, darkness). “Light” and “darkness” are immediately evocative of Invisible Man. The nameless protagonist famously wires the dark “hole” he lives in with “1,369 lights”;9 light and darkness are further used as symbols throughout the novel. “Streets” is about as evocative of The Foxes of Harrow, which has a particular focus on the urban landscape of New Orleans. Taken literally, “light,” “darkness,” and “air” can also refer to the outside world. Here, I note that Yerby’s novel moves between New Orleans and the nearby Harrow plantation, and that even the title suggests an emphasis on setting.
All in all, the surface-level reading that men and women write about different topics is disproven by examining the data in more detail. The gender division occurring in Figure 2 is the result of a combination of factors that include unconscious style, symbolism of light and darkness, and a focus on urban setting. There are, of course, more factors at play; I invite the reader to use Stylometric Analysis Explorer to explore these factors.
Chrono-Stylometric Drift: Unconscious Style, or Something Else?
Looking at Figure 1, you may notice Iola Leroy; or, Shadows Uplifted by Frances E. W. Harper (W_Harper_Iola_1892) as a text which, in contrast to the gender division discussed above, is consistently grouped together with novels written by men. If we stop to look closer, we can see that Iola Leroy is in fact grouped together with nineteenth-century novels like itself. Figure 4 attests to this observation; starting from 100 MFW all the way to the 2000 MFW stratum, nineteenth- and early-twentieth-century novels are largely grouped together. Iola Leroy is surrounded by books by male authors simply as a corollary of the sizable temporal gap between itself and the other women-written novels in our corpus of 42 books, with the 1928 Quicksand being the next earliest publication.
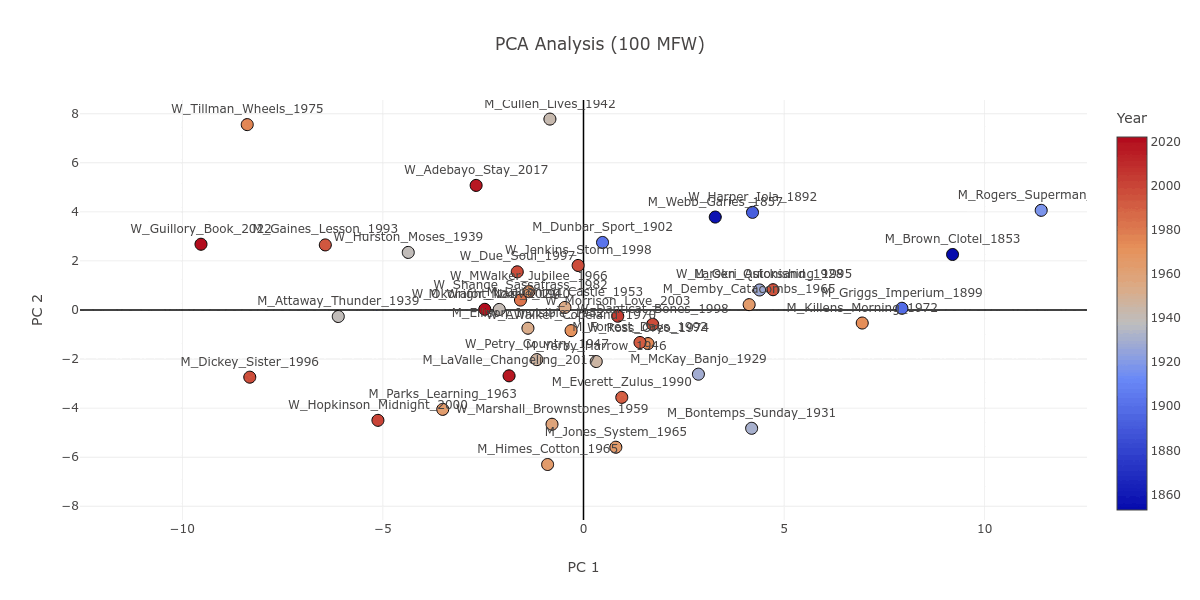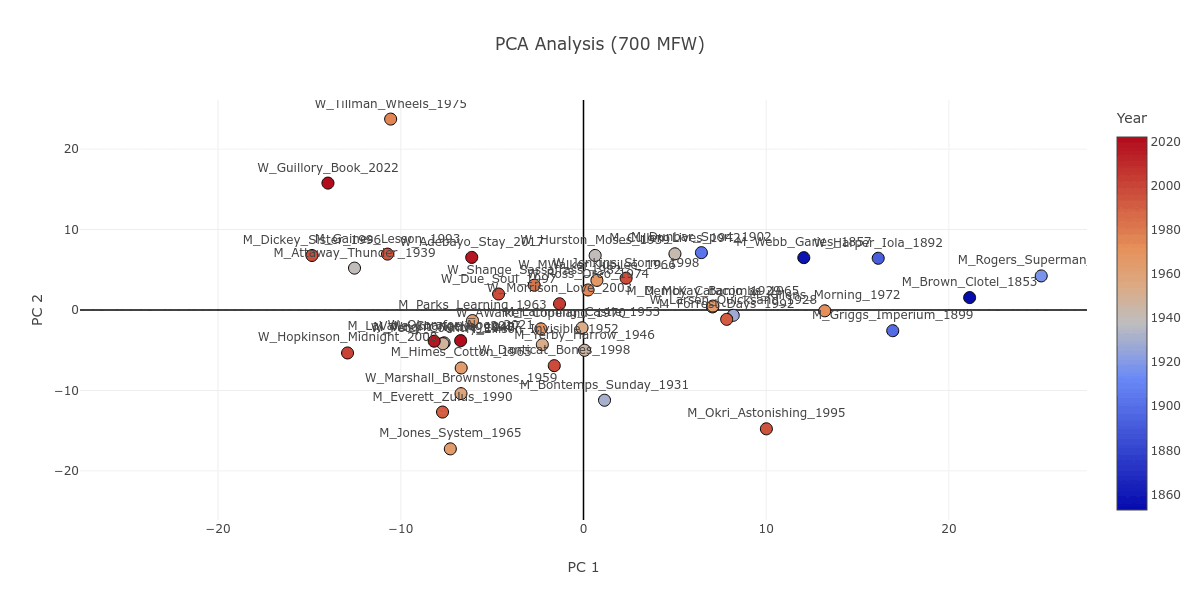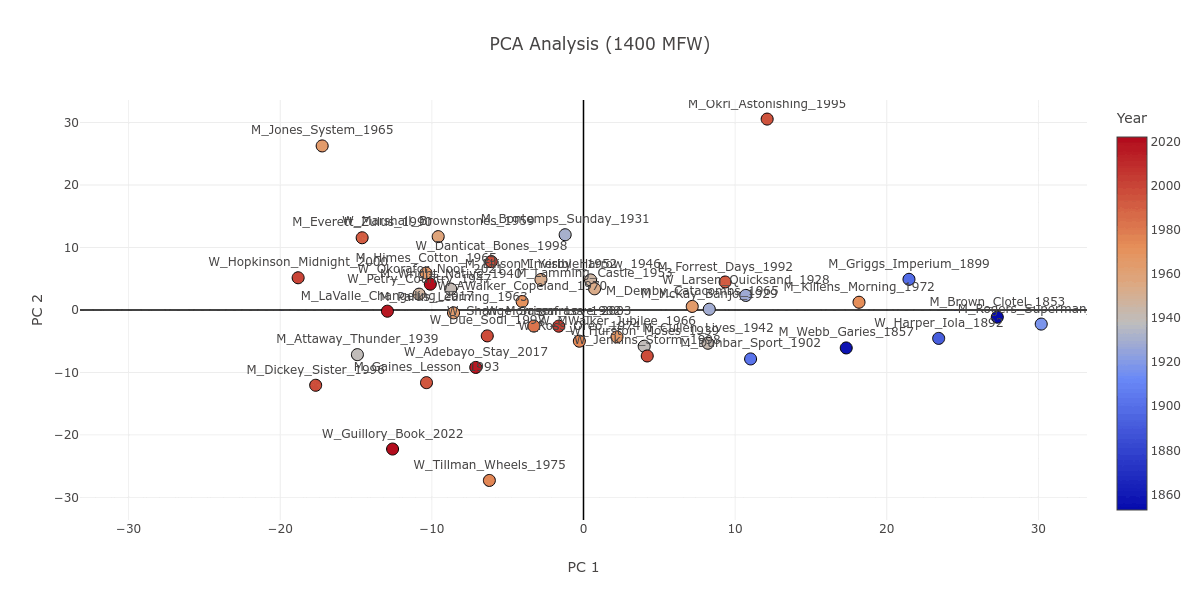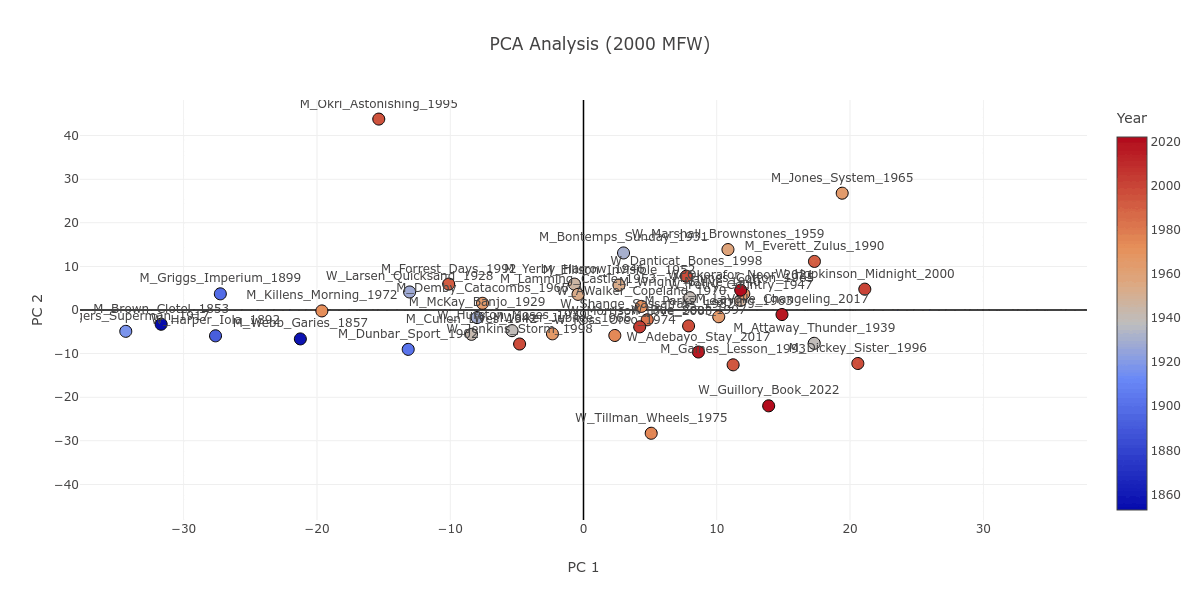
Figure 4. The PCA plot as it progresses from 100 to 2000 MFW, with the novels color coded in a gradient from blue to red based on their publication dates, which reflects the earliest and latest novels respectively.
As Figure 5 shows, the PC1 axis, which is the vehicle of the chronological division among our 42 novels, seems to be mainly (albeit not exclusively) driven by low semantic value function words, which we associate with unconscious style regardless of the MFW stratum. It may be said, then, that the chronological style drift over time observed in this plot has its roots in how Black authors of different periods have approached the English language. Robert A. Bone argues in the 1958 The Negro Novel in America—one of the earliest book-length studies of its kind—that Black novelists relied on a “stylistic imitation” of the Victorian novel’s language until the 1920s.10 Such Victorian style is nowhere to be found in Richard Wright’s Native Son (M_Wright_Native_1940), which makes liberal use of African-American Vernacular English to faithfully represent working-class Black life in the Chicago of the 1930s, or in LeRoi Jones (Amiri Baraka)’s The System of Dante’s Hell (M_Jones_System_1965), which experiments with the very form of written English.11
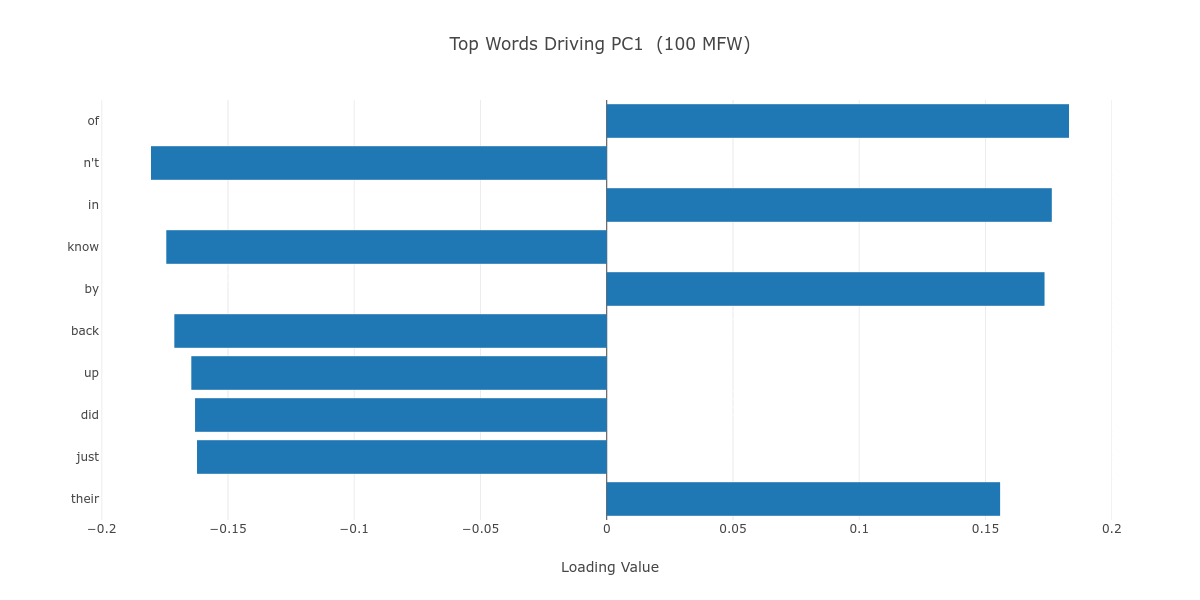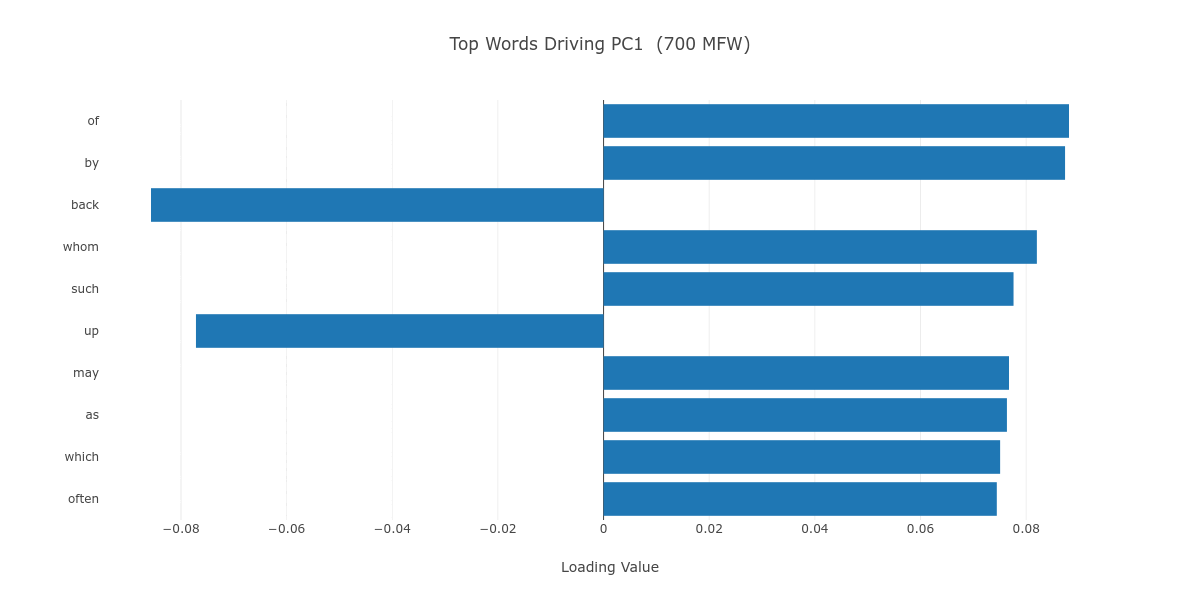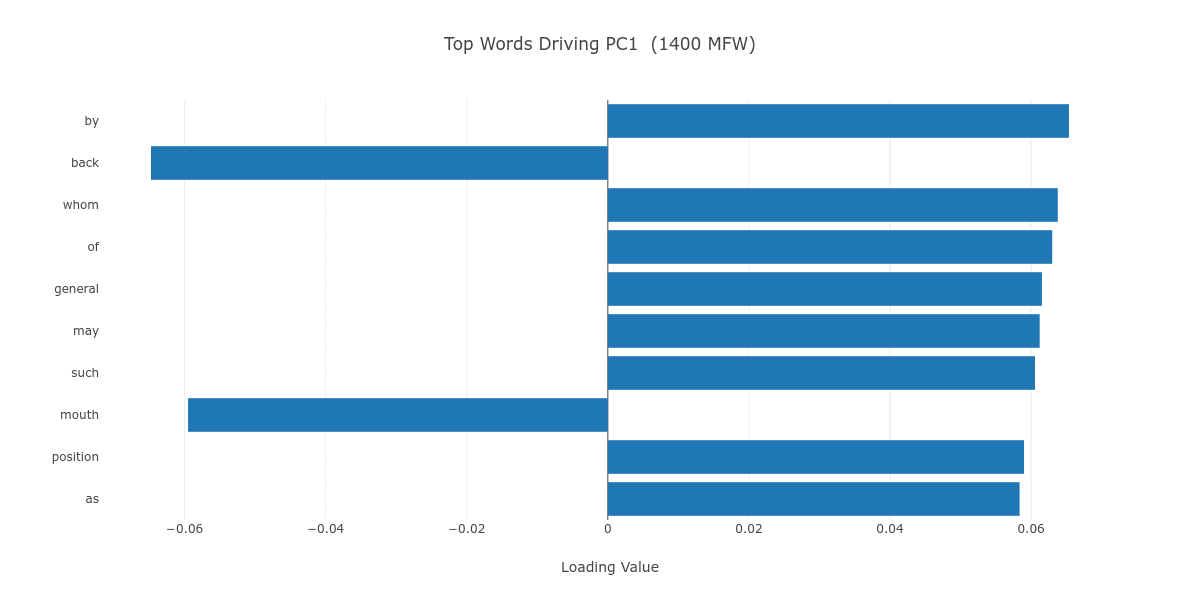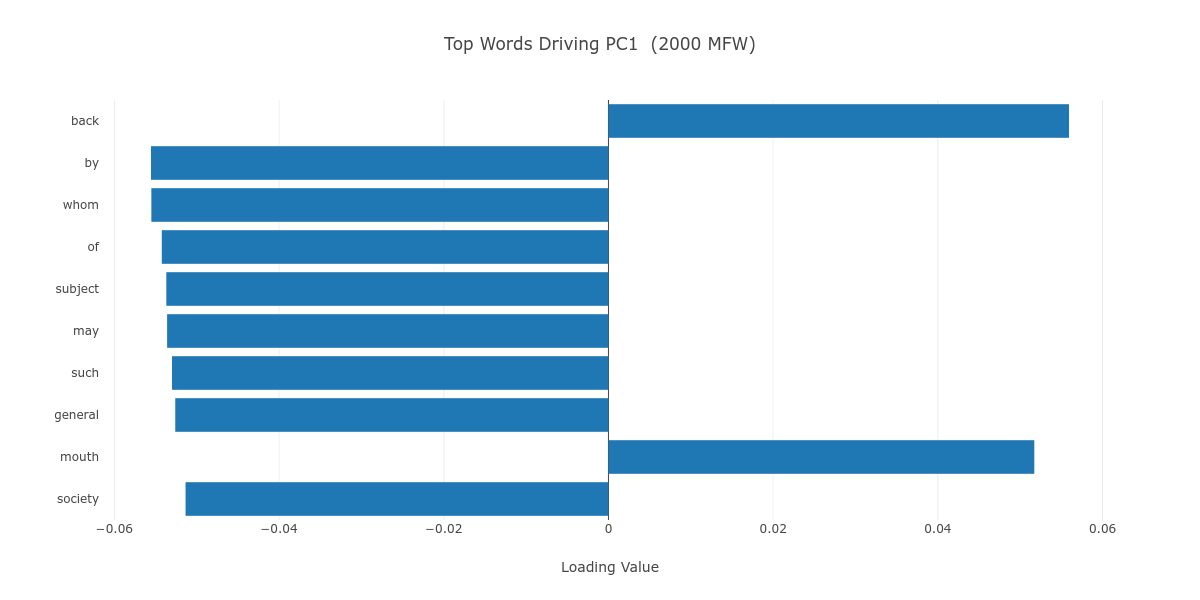
Figure 5. The top ten loadings of PC1, in a progression from 100 to 2000 MFW.
It is difficult not to notice M_Killens_Morning_1972 (John Oliver Killens’s Great Gittin’ Up Morning, a biographical novel about the Black insurrectionist Denmark Vesey) as a relatively reddish dot among the blue dots of nineteenth- to early-twentieth-century novels, which cluster together on the center-right of the plot up until the 1800 MFW stratum, and on the center-left thereafter. Killens writes in the foreword to Great Gittin’ Up Morning that he based the book’s later chapters on Vesey’s 1822 trial records.12 Using a nineteenth-century document as a historical source may have led Killens to subconsciously borrow from a nineteenth-century style of writing.
Or, perhaps more convincingly, the grouping of Great Gittin’ Up Morning with early Black novels may have to do with content, even though PC1 is primarily driven by low semantic value words. We can look at the most distinctive words of Great Gittin’ Up Morning on the low MFW stratum of 500, as a case in point. If we compare them to the most distinctive words of William Wells Brown’s Clotel; or, the President’s Daughter (M_Brown_Clotel_1853), we learn that both novels share “slaves” as a distinctive word (see Figure 6).
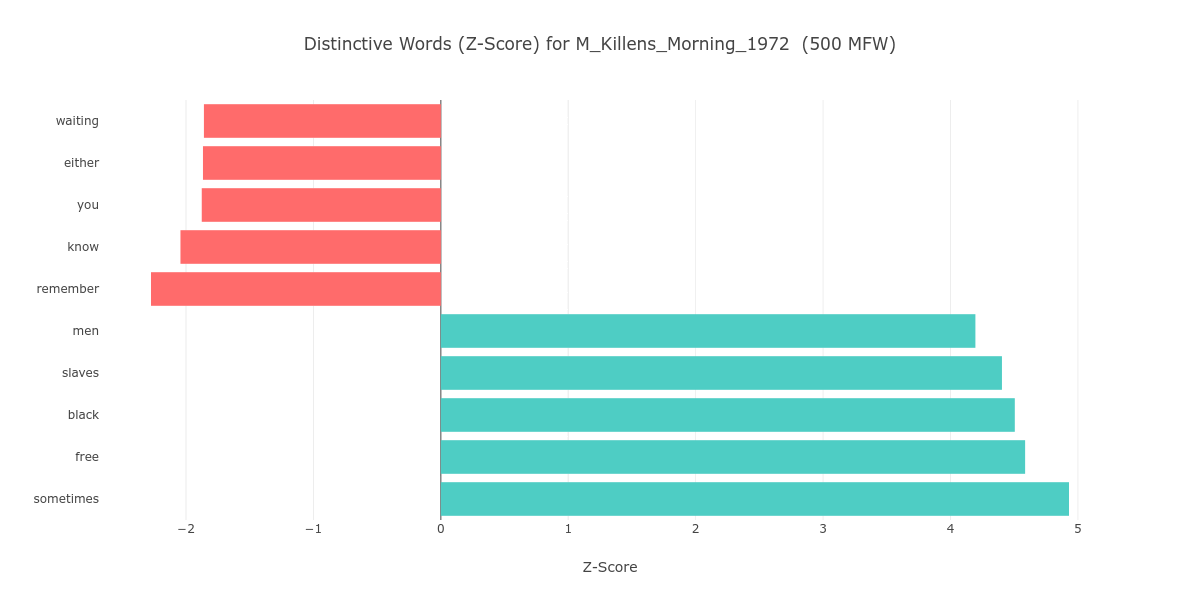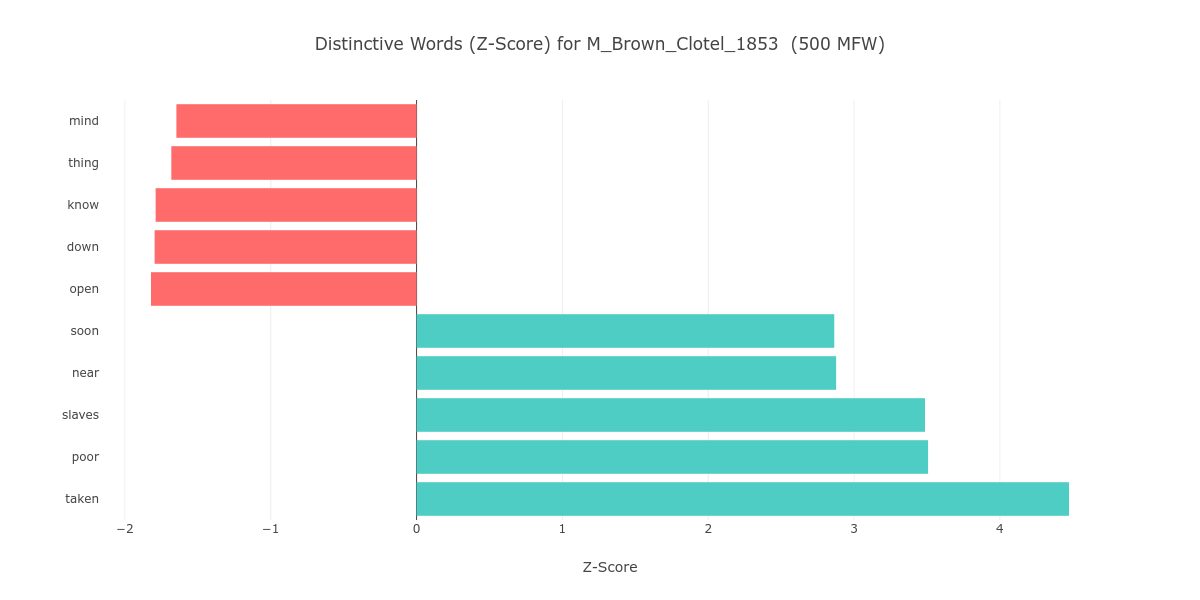
Figure 6. The most distinctive words (based on top 5 negative and positive z-scores) of Great Gittin’ Up Morning and Clotel on the 500 MFW stratum, in two-second intervals.
Additionally, it is noteworthy that both Great Gittin’ Up Morning and Clotel include “know” in their top negative z-scores, meaning that the absence of the verb “know” is a distinctive feature of both novels. “Know” also appears as a top contributor to PC1 on lower MFW strata (see Figure 5). This absence could be linked to the restriction of knowledge (of ancestral history and personal identity, for instance) with which slavery was systematically entrenched.
To be sure, Killens’s novel doesn’t share distinctive words (positive or negative) with any other novel in the nineteenth- to early-twentieth-century cluster on the 500 MFW stratum. Nevertheless, we know that other books in the cluster, like Iola Leroy and Sutton E. Griggs’s Imperium in Imperio (M_Griggs_Imperium_1899), discuss the topics of slavery and freedom at length. Thus, this cluster likely emerges due to both unconscious style and content.
Conclusion
With this blog post, it is my intention to underscore the viability of applying computational methods to the Black novel. Even this small dataset of 42 novels reveals fascinating patterns. This has to do with the fact that all these novels belong to a Black tradition, regardless of differences in gender, publication date, and the like.
You might have noticed that some novels seem to be stylistic outliers. Namely, Carolyn Tillman’s Life on Wheels (W_Tillman_Wheels_1975) is a consistent anomaly across MFW strata, and Ben Okri’s Astonishing the Gods (M_Okri_Astonishing_1995) strays far from the crowd on higher MFW strata. These anomalies are worthy of further examination, as they raise interesting questions about style. Think: Tillman’s semi-autobiographical novel relates the story of a woman confined to a wheelchair; is it this focus on disabled embodiment which gives rise to the novel’s stylistic uniqueness, and how? Or: What exactly is it about the content of Okri’s novel that is so different from the rest of the 42 books—is it just the content that differs? In the next blog post, I will attempt to answer such questions (again, using computational methods).
Notes
-
“Distant” as in digital humanities pioneer Franco Moretti’s famous coinage, “distant reading.” I mean to say that I will apply computational methodology to survey all 42 books at once, instead of close reading a few of them. ↩
-
Mendenhall, T. C. “The Characteristic Curves of Composition.” Science, vol. 9, no. 214, 1887, pp. 237–49. ↩
-
As just two examples of this kind of computational literary studies scholarship, see Matthew L. Jockers’s Macroanalysis: Digital Methods and Literary History (2013) and Andrew Piper’s Enumerations: Data and Literary Study (2018). ↩
-
NLP is a branch of machine learning/artificial intelligence working to improve computers’ capacity to process human language, as well as to leverage this capacity to interpret and generate human language. ↩
-
This is a very simplified explanation of the z-score normalization procedure for the sake of brevity; thus, it misses important nuances. For a more detailed explanation, which comes complete with Python code, please read the section on John Burrows’s Delta method in François Dominic Laramée’s Programming Historian tutorial, “Introduction to stylometry with Python”. ↩
-
Readers familiar with the field of stylometry will notice that this is the underlying logic of John Burrows’s Delta method. See Burrows, John. “‘Delta’: A Measure of Stylistic Difference and a Guide to Likely Authorship.” Literary and Linguistic Computing, vol. 17, no. 3, Sep. 2002, pp. 267–87. ↩
-
Some readers may notice that this is the formula for Manhattan distance. ↩
-
Ellison, Ralph. Invisible Man. 1952. 2nd ed., Vintage Books, 1995. ↩
-
Bone, Robert A. The Negro Novel in America. Yale University Press, 1958. ↩
-
See this excerpt from The System of Dante’s Hell, page 126: “He pointed, like Odysseus wd. Like Virgil, the weary shade, at some circle. For Dante, me, the yng wild virgin of the universe to look. To see what terror. What illusion. What sudden shame, the world is made. Of what death and lust I fondled and thot to make beautiful or escape, at least, into some other light, where each death was abstract & intimate.” Jones’s sentence fragments and frequent abbreviations of words clearly distinguishes it from nineteenth- and early-twentieth century Black novels. Jones, LeRoi. The System of Dante’s Hell. Grove Press, Inc., 1965. ↩
-
Killens, John Oliver. Great Gittin’ Up Morning. Doubleday & Company, Inc., 1972. ↩